
This article explores the different approaches to code obfuscation, their advantages and disadvantages.
Code obfuscation is a powerful tool for protecting apps from reverse engineering and manipulation. It’s a critical component of almost all app security and copy protection tools. Without obfuscation, the application or security code is transparent, easily understood, and therefore relatively easily modified. But there are several different approaches to code obfuscation, and each comes with inherent advantages or disadvantages.
Let’s look at how a typical compiler operates and therefore what opportunities are provided for obfuscating code:

How a typical compiler operates
The above diagram shows that a typical compiler (e.g. Clang) consists of a ‘frontend’ which parses the source code, compiles it into an ‘intermediate’ level, and a ‘backend’ which optimizes and produces the final machine code in an executable format (‘binary’) suitable for the machine to run.
This provides three places where obfuscation could be done:
- Source level: i.e. changing the source code before it is compiled by the frontend.
- Intermediate level, i.e. manipulating the intermediate representation before the backend uses it to create the binary.
- Binary level, i.e. modifying the binary directly after compilation and before it is distributed.
Most application protection products choose to do this at the intermediate level, and for good reasons:
- Intermediate is nearly always Low Level Virtual Machine (LLVM) which is open source and comes with a rich set of libraries allowing an easy level of entry into writing your obfuscator.
- Both Android and iOS use the LLVM-based Clang compiler allowing the two most popular OS platforms to be targeted with the same code base.
Very few vendors offer source-level obfuscators for compiled languages, because it’s much easier to operate at the LLVM level, and maintaining 100% compatibility with languages like C++ is a lot of work. A further disadvantage with this approach is that you’re very tied to that source language – so Swift comes along and suddenly your product is obsolete and can’t be quickly rewritten.
Source-level obfuscators are popular, though, for script languages like Javascript, since there’s no other option. In this case, obfuscation is even more important since the source code itself is distributed and not a compiled binary.
Finally, we come on to binary level obfuscators which are quite a rarity because they are hard to create and typically must cater to multiple machine code instruction sets e.g. ARM64, Intel X86_64, Arm V7 (32 bit), etc. They also must be able to accurately read and rewrite the various binary formats supported e.g. ELF on Android and Mach-O on iOS/MacOS. There are many complexities in this process that somebody using LLVM simply does not have to worry about.
However, binary level obfuscators offer some tremendous benefits:
- They are not tied to the toolchain and so, in theory, can protect binaries from any compiler e.g. Swift, C/C++, Rust, Golang, Dart, Xamarin, Unity etc.
- They are also not dependent on any development tools and therefore protection can be run entirely independently of the development process e.g. by an IT Security function rather than developers.
- Because they are dealing with actual machine code instructions, they can achieve finer-grained obfuscation than is possible at the intermediate level and certainly way beyond what is possible at the source level.
This table summarises the relative advantages and disadvantages:
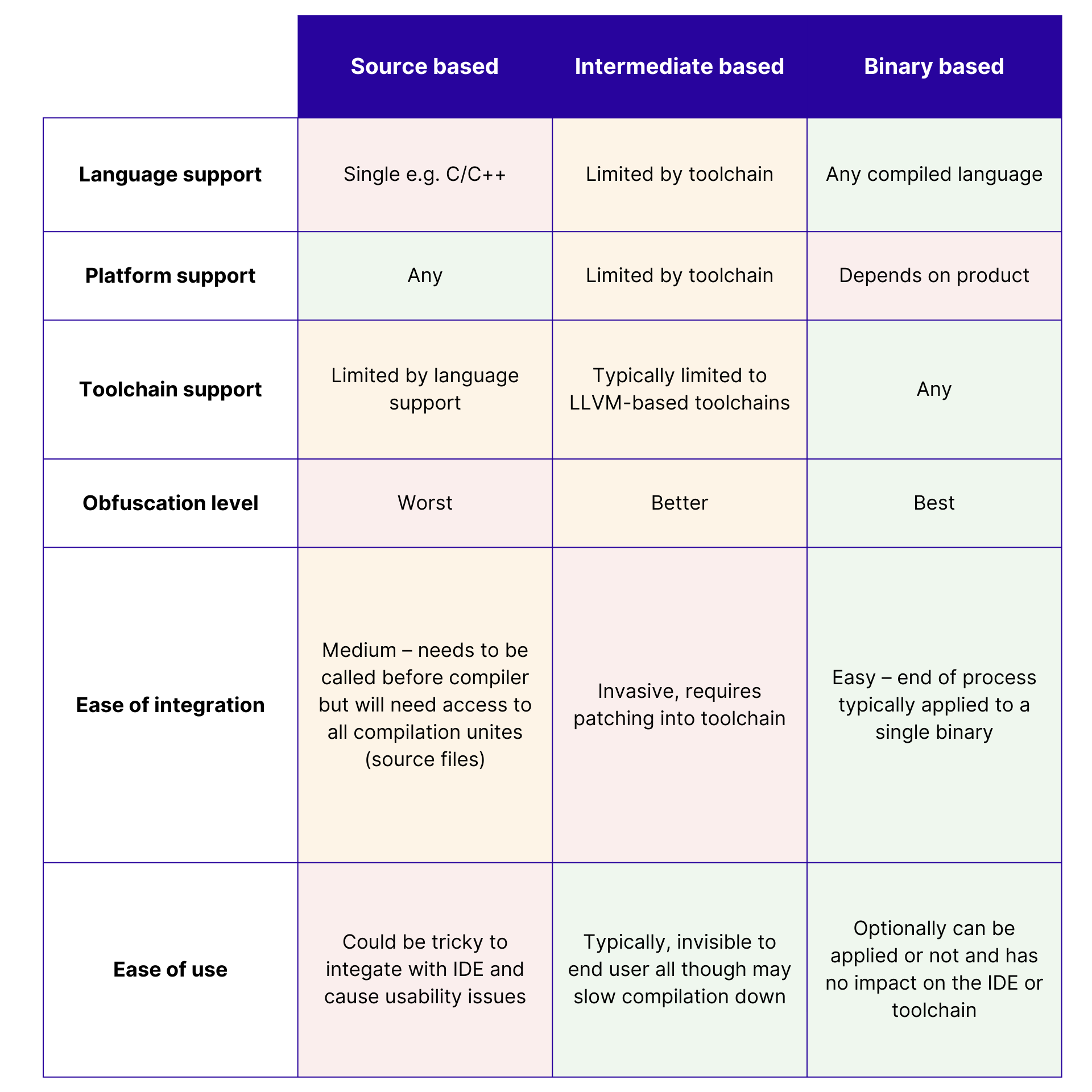
Advantages and disadvantages of different levels of obfuscators
As a user, I would look for a binary-level obfuscator as it is the most versatile and has many benefits, whereas as a tool vendor, I would choose intermediate as it is the easiest to develop and maintain.
The biggest risk with an intermediate-level obfuscator is that your target tool vendor decides to drop support for LLVM as we’ve recently seen with Apple and Xcode. It will be interesting to see how those vendors deal with that.



